
Wie filtert Google ähnliche Inhalte innerhalb derselben Website?
Google hat Mechanismen entwickelt, um ähnliche Inhalte auf einer Website zu erkennen und zu filtern. Dieser Text erklärt, wer die Verfahren nutzt, wie der Suchalgorithmus arbeitet, welche technischen und redaktionellen Folgen das für Betreiber hat und welche Werkzeuge zur Content-Analyse eingesetzt werden können.
Wie Google ähnliche Inhalte erkennt und clustert
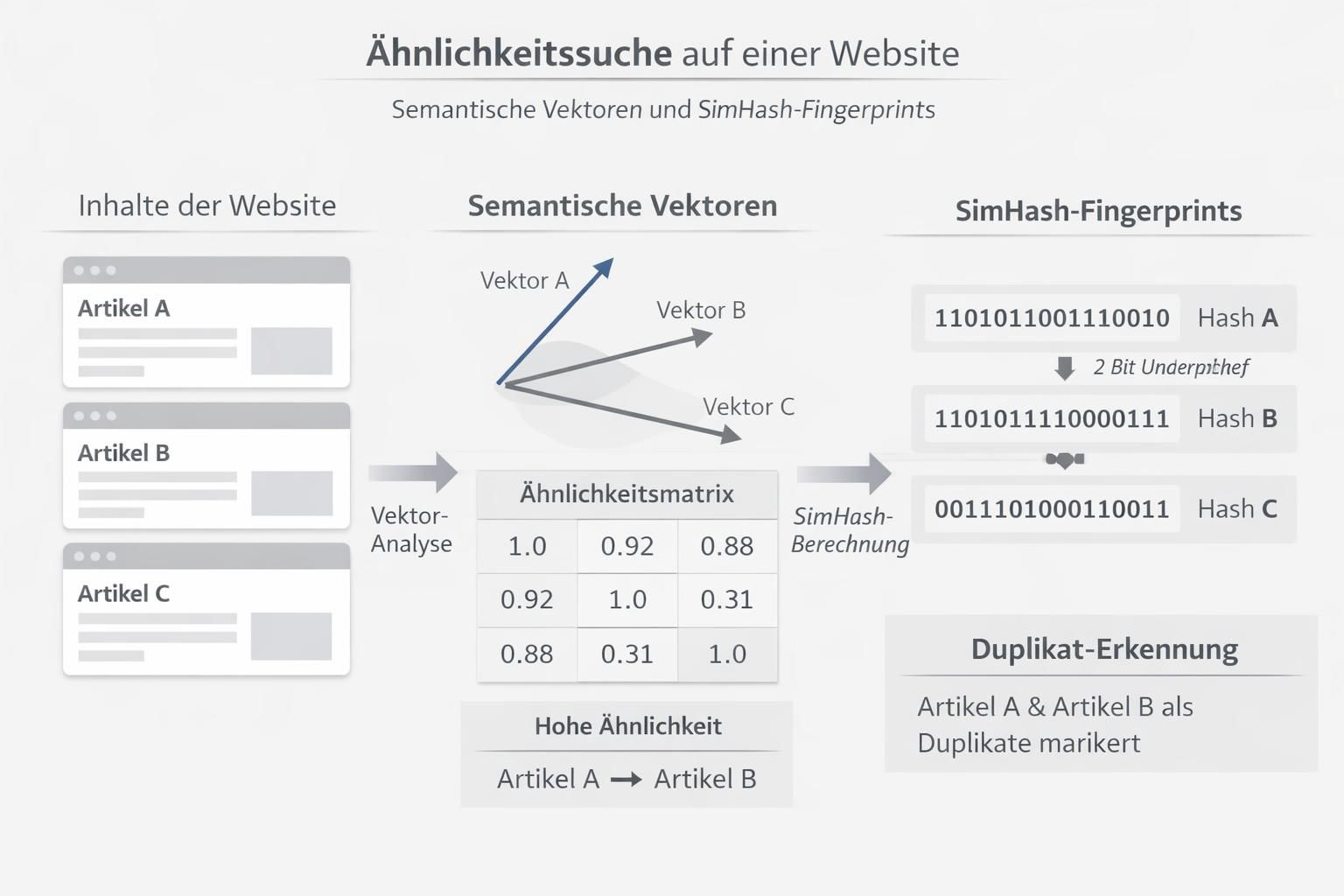
Der Kern des Verfahrens liegt in der Kombination aus semantischer Analyse und technischen Fingerabdrücken. Zunächst übersetzt Google Text in Vektoren, um Bedeutung statt bloße Wortfolgen zu vergleichen.
Vektoren und SimHash im Filterprozess
Mit Vektor-Modellen prüft der Index, ob zwei Seiten inhaltlich dasselbe Nutzerziel bedienen. Im zweiten Schritt kommt SimHash zum Einsatz: Dieser Algorithmus erzeugt kompakte Hashwerte, die ein schnelles Vergleichen großer Textmengen erlauben.
Der Crawler sammelt Inhalte, berechnet Hashes und ordnet ähnliche Seiten in Clustern. Für Betreiber bedeutet das: Bei hohem Ähnlichkeitsgrad wird nur eine Variante zur Indexierung bevorzugt, andere werden gefiltert.
Beispielhaft kann ein deutscher Onlinehändler mit Produktvarianten erleben, dass nahezu identische Beschreibungen verschiedener URLs intern konkurrieren und Sichtbarkeit verlieren. Insight: Wer die semantische Nähe seiner Seiten kennt, kann gezielt Prioritäten setzen.
Technische Signale, die das Filtern steuern
Google beachtet neben semantischer Nähe auch technische Hinweise: Canonical-Tags, 301-Weiterleitungen, hreflang- und robots-Anweisungen geben klare Signale darüber, welche URL bevorzugt werden soll.
Indexierung, Crawl-Budget und URL-Parameter
Fehlerhafte URL-Strukturen, CMS-generierte Druckansichten oder Tracking-Parameter führen zu internem Duplicate Content. Tools wie Screaming Frog oder die Google Search Console helfen, solche Varianten aufzuspüren und Parameter zu deklarieren.
Bei großen Shops verteilt sich Linkkraft, wenn mehrere Versionen zugänglich sind; dadurch leidet das Ranking. Korrekt gesetzte Canonicals oder dauerhafte 301-Weiterleitungen bündeln Signale und reduzieren unnötige Crawls.
Insight: Technische Konsistenz ist Voraussetzung, damit der Crawler effizient indeksiert und der Suchalgorithmus die richtige Version auswählt.
Content-Analyse und redaktionelle Maßnahmen gegen Duplicate Content
Automatisch erzeugte Texte führen häufig zu sogenanntem near duplicate content. Für Redaktionen und SEO-Teams ist deshalb eine laufende Content-Analyse Pflicht.
Praktische Schritte: Erkennen, Überarbeiten, Priorisieren
Zur Erkennung dienen Werkzeuge wie Copyscape, Siteliner, Semrush oder Ahrefs. Sie zeigen externe und interne Übereinstimmungen und geben Prioritäten für Überarbeitungen.
Redaktionell heißt das: Unique Content schaffen, KI-Varianten mit Fakten anreichern und semantisch unterschiedliche Zielsetzungen formulieren. Techniken wie Cross-Domain-Canonical oder Noindex für Tag-Archive verhindern ungewollte Indexierung.
Für SEO bedeutet das konkret geringere Ranking-Konkurrenz zwischen eigenen Seiten, bessere Nutzung des Crawl-Budgets und Erhalt von Linkautorität. Insight: Kombinierte technische und redaktionelle Maßnahmen schützen die Sichtbarkeit nachhaltig.
Praxisbeispiel für ein typisches Szenario
Ein mittelgroßer Shop bemerkt in der Search Console, dass Google eine andere URL als kanonisch auswählt. Nach Crawl-Analyse werden Canonicals gesetzt, Tag-Seiten auf Noindex gestellt und mehrere Produkttexte überarbeitet.
Ergebnis: Die bevorzugte URL gewinnt an Sichtbarkeit, das Crawl-Budget wird entlastet und die Domain-Authority bleibt konzentriert. Insight: Kurzfristige Aufwand reduziert langfristige Risiken wie Deindexierung oder Rankingverlust.





